协程简介
本文简单介绍了协程的基本概念和实现原理。
基础知识
在学习协程之前,我们需要了解一些基本的知识,帮助我们理解协程。
应用程序和内核
内核具有最高权限,可以访问受保护的内存空间,可以访问底层的硬件设备。而这些是应用程序所不具备的,但应用程序可以通过调用内核提供的接口来间接访问或操作。以一次网络 IO 请求过程中的 read 操作为例,请求数据会先拷贝到系统内核的缓冲区(内核空间),再从操作系统的内核缓冲区拷贝到应用程序的地址空间(用户空间)。而从内核空间将数据拷贝到用户空间过程中,就会经历两个阶段:
- 等待数据准备
- 拷贝数据
也正因为有了这两个阶段,才提出了各种网络 IO 模型。
同步和异步
同步(Synchronised)和异步(Asynchronized)的概念描述的是应用程序与内核的交互方式,同步是指应用程序发起 IO 请求后需要等待或者轮询内核 IO 操作返回结果后才能继续执行;而异步是指应用程序发起 IO 请求后仍继续执行,当内核 IO 操作完成后会通知应用程序,或者调用应用程序的回调函数。同步和异步是相对于操作结果来说,会不会等待结果返回。
阻塞和非阻塞
阻塞和非阻塞的概念描述的是应用程序调用内核 IO 操作的方式,阻塞是指 IO 操作需要彻底完成后才返回到用户空间;而非阻塞是指 IO 操作被调用后立即返回给用户一个状态值,无需等到 IO 操作彻底完成。
并发
在操作系统中,并发是指 一个时间段 中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
并发和并行的区别:
- 并发(concurrency):逻辑上具备同时处理多个任务的能力。
- 并行(parallesim):物理上在同一时刻执行多个并发任务,依赖多核处理器等物理设备。
协程的基本概念
我们可以看一下维基百科中对协程的定义:
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing multiple entry points for suspending and resuming execution at certain locations. Coroutines are well-suited for implementing more familiar program components such as cooperative tasks, exceptions, event loops, iterators, infinite lists and pipes.
协程是一种程序组件,是由子例程(过程、函数、例程、方法、子程序)的概念泛化而来的,子例程只有一个入口点且只返回一次,而协程允许多个入口点,可以在指定位置挂起和恢复执行。
简而言之,协程在行为逻辑上和线程、进程类似,都是实现不同逻辑流的切换和调度。但要明确的是,协程(Coroutine)编译器级的,进程(Process)和线程(Thread)操作系统级的。
引入协程的目的
在没有协程的时代,为了应对 IO 操作,主要有三种模型
- 同步编程:应用程序等待IO结果(比如等待打开一个大的文件,或者等待远端服务器的响应),阻塞当前线程;
- 优点:符合常规思维,易于理解,逻辑简单;
- 缺点:成本高昂,效率太低,其他与IO无关的业务也要等待IO的响应;
- 异步多线程/进程:将IO操作频繁的逻辑、或者单纯的IO操作独立到一/多个线程中,业务线程与IO线程间靠通信/全局变量来共享数据;
- 优点:充分利用CPU资源,防止阻塞资源
- 缺点:线程切换代价相对较高,异步逻辑代码复杂
- 异步消息+回调函数:设计一个消息循环处理器,接收外部消息(包括系统通知和网络报文等),收到消息时调用注册的回调函数;
- 优点:充分利用CPU资源,防止阻塞资源
- 缺点:代码逻辑复杂
协程的概念,从一定程度来讲,可以说是“用同步的语义解决异步问题”,即业务逻辑看起来是同步的,但实际上并不阻塞当前线程(一般是靠事件循环处理来分发消息)。协程就是用来解决异步逻辑的编程复杂度问题的。
优点
- 协程更加轻量,创建成本更小,降低了内存消耗
- 协程有自己的调度器,减少了 CPU 上下文切换的开销,提高了 CPU 缓存命中率
- 减少同步加锁,整体上提高了性能
- 可以按照同步思维写异步代码,即用同步的逻辑,写由协程调度的回调
缺点
- 在协程执行中不能有阻塞操作,否则整个线程被阻塞
- 协程可以处理 IO 密集型程序的效率问题,但不适合处理 CPU 密集型问题
适用场景
- 高性能计算,牺牲公平性换取吞吐。
- 在 IO 密集型的热舞
- Generator 式的流式计算
实现原理
线程模型
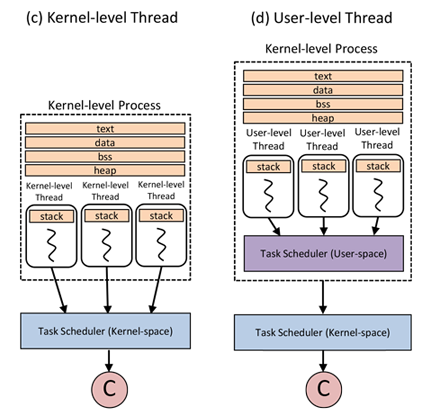
在现代计算机结构中,先后提出过两种线程模型:用户级线程(user-level threads)和内核级线程(kernel-level threads)。
用户级线程是指,应用程序在操作系统提供的单个控制流的基础上,通过在某些控制点(比如系统调用)上分离出一些虚拟的控制流,从而模拟多个控制流的行为。用户级线程模型的优势是线程切换效率高,因为它不涉及系统内核模式和用户模式之间的切换;另一个好处是应用程序可以采用适合自己特点的线程选择算法,可以根据应用程序的逻辑来定义线程的优先级,当线程数量很大时,这一优势尤为明显。但是,这同样会增加应用程序代码的复杂性。用户级线程本身只有一个线程,所以无法实现并行。
内核级线程往往指操作系统提供的线程语义,由于操作系统对指令流有完全的控制能力,甚至可以通过硬件中断来强迫一个进程或线程暂停执行,以便把处理器时间移交给其他的进程或线程,所以,内核级线程有可能应用各种算法来分配处理器时间。线程可以有优先级,高优先级的线程被优先执行,它们可以抢占正在执行的低优先级线程。在支持线程语义的操作系统中,处理器的时间通常是按线程而非进程来分配,因此,系统有必要维护一个全局的线程表,在线程表中记录每个线程的寄存器、状态以及其他一些信息。然后,系统在适当的时候挂起一个正在执行的线程,选择一个新的线程在当前处理器上继续执行。
原理
协程(Coroutine)是一种轻量级的用户级线程,实现的是非抢占式的调度,即由当前协程切换到其他协程由当前协程来控制。目前的协程框架一般都是设计成 1:N 模式。所谓 1:N 就是一个线程作为一个容器里面放置多个协程。那么谁来适时的切换这些协程?答案是有协程自己主动让出 CPU,也就是每个协程池里面有一个调度器,这个调度器是被动调度的。意思就是他不会主动调度。而且当一个协程发现自己执行不下去了(比如异步等待网络的数据回来,但是当前还没有数据到),这个时候就可以由这个协程通知调度器,这个时候执行到调度器的代码,调度器根据事先设计好的调度算法找到当前最需要 CPU 的协程。切换这个协程的 CPU 上下文把 CPU 的运行权交个这个协程,直到这个协程出现执行不下去需要等等的情况,或者它调用主动让出 CPU 的 API 之类,触发下一次调度。
源代码分析
由于操作系统并不支持协程,协程是由编程语言来实现的,python、lua、go、c++ 都包含对协程的支持。
目前看到大概有四种实现协程的方式:
- 利用 glibc 的
ucontext组件(skynet) - 使用汇编代码来切换上下文(libco)
- 利用 C 语言语法
switch-case的奇淫技巧来实现(Protothreads) - 利用了 C 语言的
setjmp和longjmp( 一种协程的 C/C++ 实现,要求函数里面使用 static local 的变量来保存协程内部的数据)
我们通过云风大神的 协程源代码,来看一下如何实现协程。
ucontext
头文件<ucontext.h>定义了两个数据结构,mcontext_t(暂时用不到)和ucontext_t和四个函数,我们分别来介绍他们的用途。
ucontext_t 结构体
typedef struct ucontext {
struct ucontext *uc_link; // context to assume when this one returns
sigset_t uc_sigmask; // signals being blocked
stack_t uc_stack; // stack area
mcontext_t uc_mcontext; // saved registers
...
} ucontext_t;
uc_link:指向当前的上下文结束时要恢复到的上下文,如果指向NULL,则表示进程在执行完当前的上下文后结束uc_sigmask: 保存该上下文阻塞的信号uc_stack: 该上下文使用的栈uc_mcontextt:保存的上下文的特定机器表示,包括调用线程的特定寄存器等
函数
int getcontext(ucontext_t *ucp)
该函数初始化ucp所指向的结构体ucontext_t(用来保存前执行状态上下文),填充当前有效的上下文
int setcontext(const ucontext_t *ucp)
函数恢复用户上下文为ucp所指向的上下文。成功调用不会返回。ucp 所指向的上下文应该是 getcontext() 或者 makecontext()产生的。
如果上下文是getcontext()产生的,切换到该上下文,程序的执行在 getcontext() 后继续执行。
如果上下文被 makecontext() 产生的,切换到该上下文,程序的执行切换到 makecontext() 调用所指定的第二个参数的函数上。当该函数返回时,我们继续传入 makecontext() 中的第一个参数的上下文中 uc_link 所指向的上下文。如果是 NULL,程序结束。
void makecontext(ucontext_t *ucp, void (*func)(void), int argc, ...)
函数修改ucp所指向的上下文,ucp 是被 getcontext() 所初始化的上下文。当这个上下文采用 swapcontext() 或者 setcontext() 被恢复,程序的执行会切换到 func 的调用,通过makecontext() 调用的 argc 传递 func 的参数。
在 makecontext() 产生一个调用前,应用程序必须确保上下文的栈分配已经被修改。应用程序应该确保 argc 的值跟传入 func 的一样(参数都是int值4字节);否则会发生未定义行为。
当 makecontext() 修改过的上下文返回时,uc_link 用来决定上下文是否要被恢复。应用程序需要在调用 makecontext() 前初始化 uc_link。
int swapcontext(ucontext_t *restrict oucp, const ucontext_t *restrict ucp)
函数保存当前的上下文到 oucp 所指向的数据结构,并且设置到 ucp 所指向的上下文。成功完成,swapcontext() 返回0。否则返回-1,并赋值合适的 errno。
协程源码实现
云风大神的库是基于ucontext封装的,部分源代码如下:
schedule 调度器
struct schedule {
char stack[STACK_SIZE]; // 原来schedule里面就已经存有了stack
ucontext_t main; // ucontext_t你可以看做是记录上下文信息的一个结构
int nco; // 协程的数目
int cap; // 容量
int running; // 正在运行的coroutine的id
struct coroutine **co; // 指向 coroutine 组的指针
};
coroutine
struct coroutine {
coroutine_func func; // 运行的函数
void *ud; // 参数
ucontext_t ctx; // 用于记录上下文信息的一个结构
struct schedule * sch; // 指向schedule
ptrdiff_t cap; // 堆栈的容量
ptrdiff_t size; // 用于表示堆栈的大小
int status; // 协程状态
char *stack; // 指向栈地址么?
};
创建新的 coroutine
// 初始化一个新的协程
struct coroutine *
_co_new(struct schedule *S , coroutine_func func, void *ud) {
struct coroutine * co = malloc(sizeof(*co));
co->func = func;
co->ud = ud;
co->sch = S;
co->cap = 0;
co->size = 0;
co->status = COROUTINE_READY;
co->stack = NULL;
return co;
}
...
int
coroutine_new(struct schedule *S, coroutine_func func, void *ud) {
struct coroutine *co = _co_new(S, func , ud);
// 如果协程数量超过 schedule 容量,需要对其扩容
if (S->nco >= S->cap) {
int id = S->cap;
S->co = realloc(S->co, S->cap * 2 * sizeof(struct coroutine *));
memset(S->co + S->cap , 0 , sizeof(struct coroutine *) * S->cap);
S->co[S->cap] = co;
S->cap *= 2;
++S->nco;
return id;
// 将新的协程加入序列中
} else {
int i;
for (i=0; i<S->cap; i++) {
int id = (i+S->nco) % S->cap;
if (S->co[id] == NULL) {
S->co[id] = co;
++S->nco;
return id;
}
}
}
assert(0);
return -1;
}
创建一个协程,该协程的会加入到schedule的协程序列中,func为其执行的函数,ud为func的函数参数。返回创建的线程在schedule中的编号。
释放当前协程
void
coroutine_yield(struct schedule * S) {
int id = S->running;
assert(id >= 0);
struct coroutine * C = S->co[id];
assert((char *)&C > S->stack);
_save_stack(C,S->stack + STACK_SIZE);
C->status = COROUTINE_SUSPEND;
S->running = -1;
swapcontext(&C->ctx , &S->main);
}
使用 swapcontext 切换上下文
恢复协程
void
coroutine_resume(struct schedule * S, int id) {
assert(S->running == -1);
assert(id >=0 && id < S->cap);
struct coroutine *C = S->co[id];
if (C == NULL)
return;
int status = C->status;
switch(status) {
// 新创建的协程
case COROUTINE_READY:
// 初始化
getcontext(&C->ctx);
C->ctx.uc_stack.ss_sp = S->stack;
C->ctx.uc_stack.ss_size = STACK_SIZE;
C->ctx.uc_link = &S->main;
S->running = id;
C->status = COROUTINE_RUNNING;
uintptr_t ptr = (uintptr_t)S;
// 构造上下文
makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32));
// 上下文切换
swapcontext(&S->main, &C->ctx);
break;
// 被挂起的协程
case COROUTINE_SUSPEND:
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size);
S->running = id;
C->status = COROUTINE_RUNNING;
// 上下文切换
swapcontext(&S->main, &C->ctx);
break;
default:
assert(0);
}
}
如果协程是新创建的,那么就需要初始化上下文结构,然后切换上下文。
结束所有协程
void
coroutine_close(struct schedule *S) {
int i;
for (i=0;i<S->cap;i++) {
struct coroutine * co = S->co[i];
if (co) {
_co_delete(co);
}
}
free(S->co);
S->co = NULL;
free(S);
}
结束协程调度器队列中的所有协程。
python 协程使用
Python 对协程的支持经历了很长的一段发展历程,其大概经历了如下阶段:
- python2.5:最初的生成器变形 yield/send,实现了协程的部分功能
- python3.4:引入标准库 asynico,提供 @asyncio.coroutine 和 yield from,还是以生成器对象为基础
- python3.5:添加了 types.coroutine 装饰器以及 async/await 关键字,确定了协程的语法
- python3.6:将 asyncio 由临时版改为了稳定版
- 除 asyncio 外,tornado 和 gevent 都实现了异步编程的功能。
yield send 实现
从某些角度来理解,协程其实就是一个可以暂停执行的函数,并且可以恢复继续执行。那么生成器的就可以实现暂停执行,如果在暂停后有办法把一些 value 发回到暂停执行的函数中,那么就实现了『协程』。于是在PEP 342中,添加了 “把东西发回已经暂停的生成器中” 的方法,这个方法就是send(),并且在 Python2.5 中得到了实现。这样就可以实现在各个生成器中交互 了,也就是形成了协程。
以下就是一个求平均值的协程:
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total / count
nums = [1, 2, 3, 4, 5, 6]
coro_avg = averager()
# 启动 generator
next(coro_avg)
for num in nums:
# 向 generator 中发送数值
try:
coro_avg.send(num)
except StopIteration as e:
print(e.value)
只要调用方不断把值发给这个协程,它就会一直接收值,然后生成结果。
yield from 实现
yield from用于重构生成器,可以像一个管道一样 将信息传递给内层协程, 并且处理好了各种异常情况。
yield from subgen() 时,subgen 会获得控制权,把产出的结果传给调用方,调用方可以直接控制 subgen。同时,gen 会阻塞,等待 subgen 终止。来看一个简单的程序:
def chain(*iterables):
for it in iterables:
yield from it
s = 'ABC'
t = tuple(range(3))
list(chain(s, t))
# 结果
['A', 'B', 'C', 0, 1, 2]
yield from的主要作用不是为了替代 for 循环,而是打开双向通道,把最外层的调用方与最内层的子生成器连接起来,这样二者可以直接发送和产出值,还可以传入异常,而不用在位于中间的协程中添加大量的处理异常代码。有了这个结构,协程可以通过以前不可能的方式委托职责。
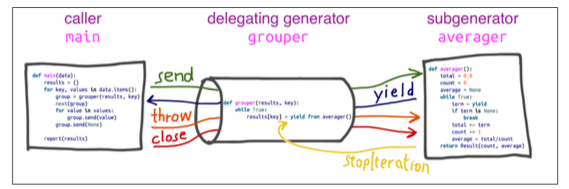
我们将上面的求均值代码用 yield from 重写:
from collections import namedtuple
Result = namedtuple('Result', 'count average')
# the subgenerator
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield
if term is None:
break
total += term
count += 1
average = total/count
return Result(count, average)
# the delegating generator
def grouper(results, key):
while True:
results[key] = yield from averager()
# the client code, a.k.a. the caller
def main(data):
results = {}
for key, values in data.items():
group = grouper(results, key)
next(group)
for value in values:
group.send(value)
group.send(None) # important!
print(results) # uncomment to debug
data={
'girls;kg': [40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m': [1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg': [39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m': [1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
asyncio 和 yield from
yield from在 asyncio 模块中得以发扬光大。之前都是我们手工切换协程,现在当声明函数为协程后,我们通过事件循环来调度协程。先看示例代码来理解一下事件循环:
import asyncio,random
@asyncio.coroutine
def smart_fib(n):
index = 0
a = 0
b = 1
while index < n:
sleep_secs = random.uniform(0, 0.2)
yield from asyncio.sleep(sleep_secs) #通常yield from后都是接的耗时操作
print('Smart one think {} secs to get {}'.format(sleep_secs, b))
a, b = b, a + b
index += 1
@asyncio.coroutine
def stupid_fib(n):
index = 0
a = 0
b = 1
while index < n:
sleep_secs = random.uniform(0, 0.4)
yield from asyncio.sleep(sleep_secs) #通常yield from后都是接的耗时操作
print('Stupid one think {} secs to get {}'.format(sleep_secs, b))
a, b = b, a + b
index += 1
if __name__ == '__main__':
loop = asyncio.get_event_loop()
tasks = [
smart_fib(10),
stupid_fib(10),
]
loop.run_until_complete(asyncio.wait(tasks))
print('All fib finished.')
loop.close()
本例中yield from后面接的asyncio.sleep()是一个coroutine(里面也用了yield from),所以线程不会等待asyncio.sleep(),而是直接中断并执行下一个消息循环。当asyncio.sleep()返回时,线程就可以从yield from拿到返回值(此处是None),然后接着执行下一行语句。
asyncio是一个基于事件循环的实现异步I/O的模块。通过yield from,我们可以将协程asyncio.sleep的控制权交给事件循环,然后挂起当前协程;之后,由事件循环决定何时唤醒asyncio.sleep,接着向后执行代码。
协程之间的调度都是由事件循环决定。
我们可以看一下运行结果:
$ python test.py
Stupid one think 0.13636436691902443 secs to get 1
Smart one think 0.1581602017832006 secs to get 1
Smart one think 0.023037176256169745 secs to get 1
Smart one think 0.052110061565446536 secs to get 2
Smart one think 0.11736072428792257 secs to get 3
Stupid one think 0.28763353153979515 secs to get 1
Smart one think 0.17820384026388691 secs to get 5
Stupid one think 0.16606243364669396 secs to get 2
Stupid one think 0.044762898267239316 secs to get 3
Smart one think 0.11746525890777898 secs to get 8
Smart one think 0.0743348356240711 secs to get 13
Stupid one think 0.15709091272898942 secs to get 5
Smart one think 0.15917070837178177 secs to get 21
Smart one think 0.06269726341203412 secs to get 34
Smart one think 0.08913987269169808 secs to get 55
Stupid one think 0.36521719056632523 secs to get 8
Stupid one think 0.2011321078378948 secs to get 13
Stupid one think 0.3807499810891797 secs to get 21
Stupid one think 0.19897080695110814 secs to get 34
Stupid one think 0.17917455468676216 secs to get 55
All fib finished.
async 和 await
弄清楚了asyncio.coroutine和yield from之后,在Python3.5中引入的async和await就不难理解了:可以将他们理解成asyncio.coroutine/yield from的完美替身。当然,从Python设计的角度来说,async/await让协程表面上独立于生成器而存在,将细节都隐藏于asyncio模块之下,语法更清晰明了。
加入新的关键字 async ,可以将任何一个普通函数变成协程。上一节中的例子可以改写为:
import time,asyncio,random
async def smart_fib(n):
index = 0
a = 0
b = 1
while index < n:
sleep_secs = random.uniform(0, 0.2)
await asyncio.sleep(sleep_secs)
print('Smart one think {} secs to get {}'.format(sleep_secs, b))
a, b = b, a + b
index += 1
async def stupid_fib(n):
index = 0
a = 0
b = 1
while index < n:
sleep_secs = random.uniform(0, 0.4)
await asyncio.sleep(sleep_secs)
print('Stupid one think {} secs to get {}'.format(sleep_secs, b))
a, b = b, a + b
index += 1
if __name__ == '__main__':
loop = asyncio.get_event_loop()
tasks = [
smart_fib(10),
stupid_fib(10),
]
loop.run_until_complete(asyncio.wait(tasks))
print('All fib finished.')
loop.close()