Git 原理解析
本文主要针对 Git 的内部实现原理进行解析。
1. Git 基础
Git 是目前世界上最优秀的分布式版本控制系统。版本控制系统是能够随着时间的推进记录一系列文件的变化以便于你以后想要的退回到某个版本的系统。
Git每一次提交都是对项目文件的一个完整拷贝,因此你可以完全恢复到以前的任一个提交而不会发生任何区别。这里有一个问题:如果我的项目大小是10M,那 Git 占用的空间是不是随着提交次数的增加线性增加呢?我提交了10次,占用空间是不是100M呢?显然不是,为了节省存储空间,Git会对每次提交的文件进行检测,如果文件没有发生变化,那么此时存储的是指向上一个版本文件的指针。
Git最适合保存文本文件,事实上Git就是被设计出来就是为了保存文本文件的,像各种语言的源代码,因为Git可以对文本文件进行很好的压缩和差异分析(大家都见识过了,Git的差异分析可以精确到你添加或者删除了某个字母)。而二进制文件像视频,图片等,Git也能管理,但不能取得较好的效果(压缩比率低,不能差异分析)。实验证明,一个 500k 的文本文件经Git压缩后仅 50k 左右,稍微改变内容后两次提交,会有两个 50k 左右的文件,没错的,保存的是完整快照。而对于二进制文件,像视频,图片,压缩率非常小, Git 占用空间几乎随着提交次数线性增长。
2. Git 文件管理流程
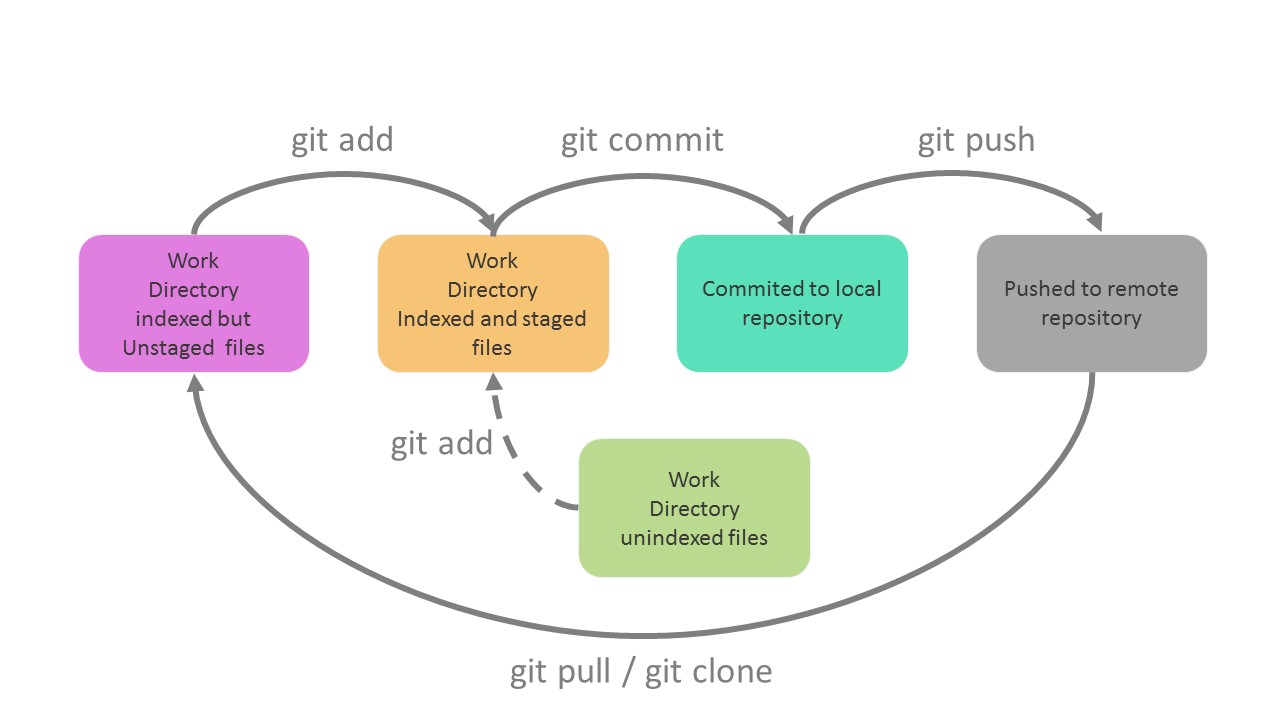
Git工程有三个工作区域:
- 工作目录:当前进行工作的区域
- 暂存区域:运行
git add命令后文件保存的区域,也是下次提交将要保存的文件 - 本地仓库:记录了你工程某次提交的完整状态和内容,这意味着你的数据永远不会丢失
相应的,文件也有三种状态:
- 已修改(modified):已修改表示修改了某个文件,但还没有提交保存
- 已暂存(staged):把已修改的文件放在下次提交时要保存的清单中,即暂存区域
- 已提交(committed):文件已经被安全地保存在本地仓库
3. Git 对象
现在已经了解了 Git 的基本流程,接下来我们需要深入内部,具体了解 Git 的实现原理。
Git 的核心部分是一个简单的键值对数据库。你可以向该数据库插入任意类型的文件,它会返回一个键值,通过该键值可以在任意时刻再次检索该文件。那么在此基础上,要实现 Git 的基本功能,我们需要解决以下三个问题:
- 数据库的实现:
- Git 是一个轻量级的版本控制系统,但传统的数据库普遍较重,不适合在 Git 中使用
- 传统数据库希望存储的元组大小尽可能一致,但文件的大小是不可控的
- 目录结构的保存:
- 数据库中的数据是平级的,但实际的文件目录是一个有层次的树结构,所以在保存文件信息的同时,要保存目录结构信息
- 提交状态的保存:
- 当使用 Git 时,我们不需要获取所有的文件信息,只需要得到某个提交节点对应的文件信息
- 当使用 Git 时,我们不需要获取所有的文件信息,只需要得到某个提交节点对应的文件信息
在 Git 中,分别使用文件对象(blob object),树对象(tree object),提交对象(commit object),解决以上三个问题。
3.1 文件对象(blob object)
虽然上文说了,Git 的核心部分是一个简单的键值对数据库,但没必要实现一个完整的数据库,Git 巧妙的利用了 Linux 系统自带文件管理系统,满足了文件存储和查找的需求。
Git 先将原始文件信息加上特定头部信息,再计算 SHA-1 校验和,作为键。之后对文件内容进行了压缩处理,作为值保存在系统中。那么 Git 是如何通过键找到值的呢?很简答,将 SHA-1 校验和作为压缩文件的文件名,利用文件管理系统实现键值映射。对这种关系抽象,就是文件对象。

我们可以通过实地操作看一下:
先通过 git init 初始化一个本地仓库,此时目录下会多了一个隐藏目录 .git,其中的 objects 子目录存储着 Git 数据库的所有内容。
$ git init
$ find .git/objects
.git/objects
.git/objects/pack
.git/objects/info
接着使用 git hash-object 直接存储对象,并返回校验和。
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
该命令输出一个长度为 40 个字符的校验和,现在我们可以查看 Git 是如何存储数据的:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
可以在 objects 目录下看到一个文件。 这就是开始时 Git 存储内容的方式——校验和的前两个字符用于命名子目录,余下的 38 个字符则用作文件名。
可以通过 cat-file 命令从 Git 那里取回数据。
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
3.2 树对象(tree object)
在解决了文件内容存储的问题后,我们来解决第二个问题——如何保存文件目录信息。
Git 在解决这个问题上采用和 Linux 类似的方法。Linux 使用 inode 存储文件的内容信息,使用 directory 存储文件的层次结构信息。而 Git 使用文件对象存储文件内容信息,使用树对象存储文件的层次结构信息。树对象的内容如下:

一个单独的树对象包含一条或多条记录,每一条记录含有一个指向文件对象或子树对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息等。
以一个简单的目录为例:
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 files
对应的文件对象(blob)和树对象(tree object)为:
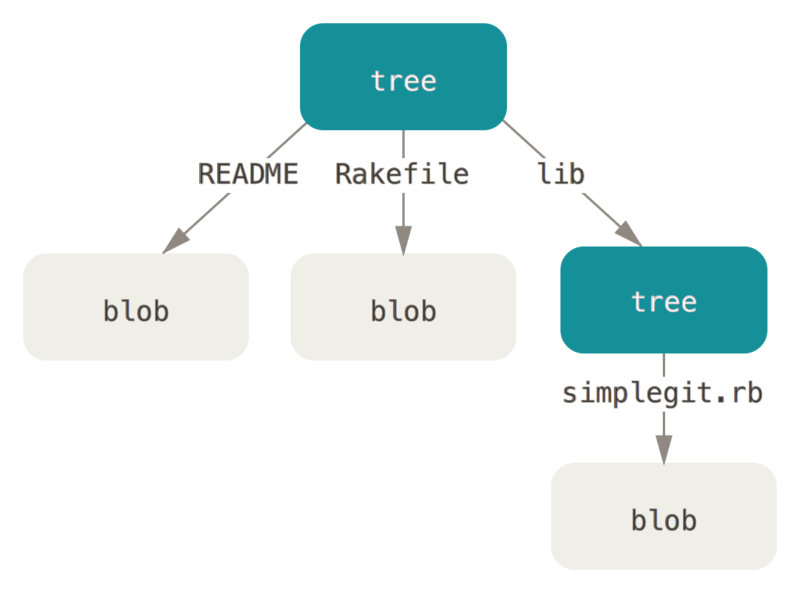
当你对文件进行修改并提交时,变化的文件会生成一个新的文件对象,记录文件的完整内容,然后针对该文件有一个唯一的 SHA-1 校验和。对于没有变化的文件,简单拷贝上一次版本的指针即 SHA-1 校验和,而不会生成一个全新的文件对象。
3.3 提交对象(commit object)
现在我们要面对第三个问题——如何得到特定提交节点的文件信息。
在之前已经通过文件对象和树对象完成了对于文件内容和文件目录结构的存储。而要得到特定提交节点的文件信息,只需要记录提交时的树对象信息,通过树对象中的指针,找到对应的文件即可——这就是提交对象。

提交对象的格式很简单:指明了该时间点项目快照的顶层树对象、作者/提交者信息。可由 git log 查看的 Git 提交历史了:
$ git log
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
跟踪对象的内部指针,将得到一个类似下面的对象关系图:
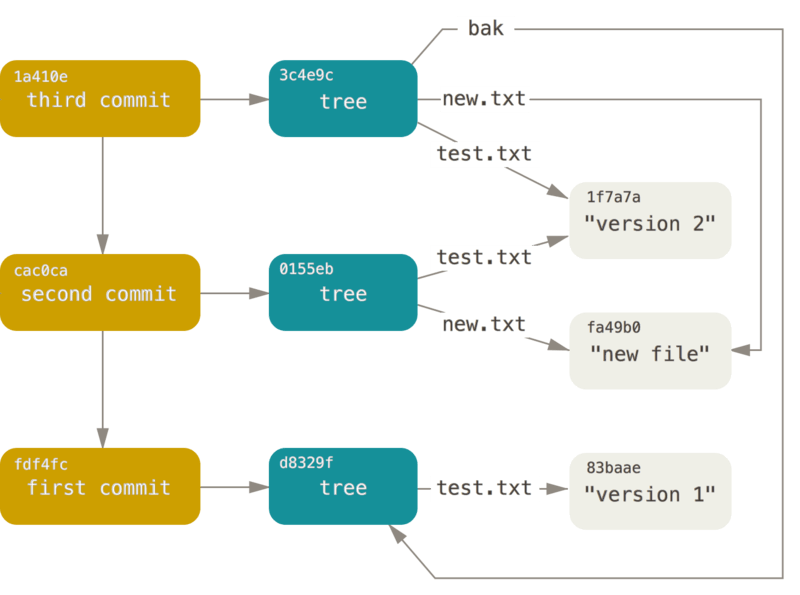
到这里,我们可以整体回顾一下 Git 保存文件的整体流程:
- 计算文件的校验和
- 如果仓库中没有储存校验和对应的文件,生成文件对象,保存文件内容
- 用树对象记录文件的目录信息
- 创建提交对象,保存本次提交的对应内容。
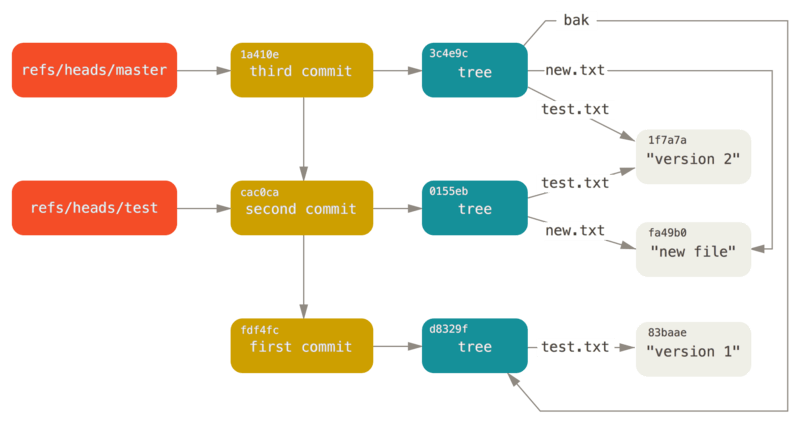
4. Git 引用
由于 Git 中所有的对象都通过 40 位的 SHA-1 校验和作为指针,当我们需要查找对应的提交对象时很不方便。因此 Git 引入引用这一概念,作为 SHA-1 校验和的别名,存储在 .git/refs 文件夹中。
最常见的引用也许就是 master了,因为这是 Git 默认创建的,它始终指向你项目主分支的最后一次提交记录。如果在项目根目录运行 cat .git/refs/heads,会输出一个 SHA-1 校验和,例如:
$ cat .git/refs/heads/master
60f13032c2ff06fc60e9bcb1e17cb48bb13d45e0
因此 master 只是一个40位 SHA-1 校验和的别名罢了。
还有一个问题,Git如何知道你当前分支的最后一次的提交ID?在 .git 文件夹下有一个 HEAD 文件,像这样:
$ cat .git/HEAD
ref: refs/heads/master
HEAD 文件其实并不包含 SHA-1 值,而是一个指向当前分支的引用,内容会随着切换分支而变化,内容格式像这样:ref: refs/heads/<branch-name>。当你执行 git commit 命令时,它就创建了一个提交对象,把这个提交对象的父级设置为 HEAD 指向的引用的 SHA-1 值。
5. Git 分支
有了以上结构的支持,在 Git 中创建分支就很容易,不需要将项目完整的拷贝一份。
5.1 创建分支
上文中已经说到,Git 通过保存文件对象来实现文件内容的保存,Git 本质上只是一棵巨大的文件树,树的每一个节点就是文件对象,而分支只是树的一个分叉。说白了,分支就是一个有名字的引用,它包含一个提交对象的的40位校验和,所以创建分支就是向一个文件写入校验和。所以自然就快了,而且与项目的复杂程度无关。
Git 的默认分支是 master,存储在 .git\refs\heads\master 文件中,假设你在 master 分支运行 git branch dev 创建了一个名字为 dev 的分支,Git 所做的实际操作是:
- 在
.git\refs\heads文件夹下新建一个文件名为dev的文本文件 - 将
HEAD指向的当前分支(当前为master)的40位SHA-1 校验和写入dev文件
创建分支就是这么简单,那么切换分支呢?更简单:
- 修改
.git文件下的HEAD文件为ref: refs/heads/<分支名称> - 按照分支指向的提交记录将工作区的文件恢复至一模一样。
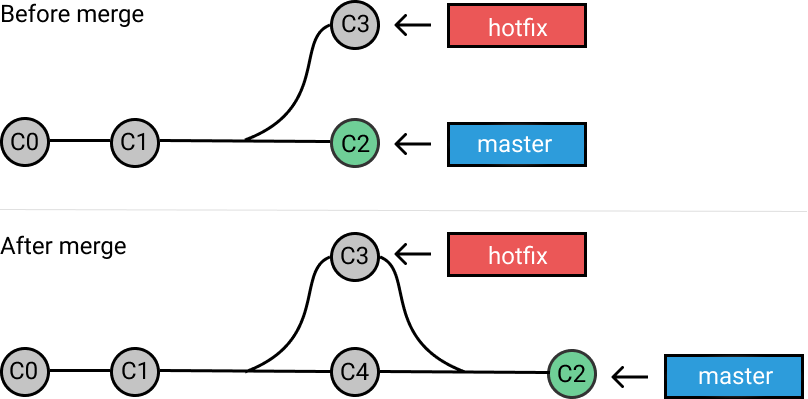
5.2 合并分支
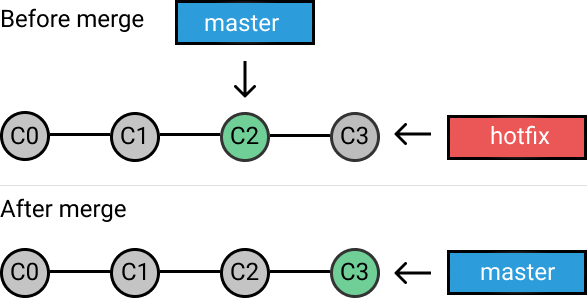
如果顺着一个分支走下去可以到达另一个分支的话,那么 Git 在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward),流程如下图所示:
当分支出现分叉时,就有可能出现冲突,Git 不得不进行一些额外处理——用两个分支的末端以及它们的共同祖先进行一次三方合并,并生成新的提交对象: