Python代码性能优化方法总结
本文简单总结了常用的python性能优化方法
Python为什么慢
在进行代码的性能优化之前,我们先简单分析Python性能较低的原因
过于强大的动态
Python是一个非常动态的语言,而这使得为Python提供JIT(Just in Time Compiler)异常困难。更加具体的内容可以阅读这篇文章why is python slow
内存分布不紧凑
由于python数据内存分布不紧凑,导致没有很好的利用L1/L2 缓存进行加速。
由于硬件技术的限制,我们可以制造出容量很小但很快的存储器,也可以制造出容量很大但很慢的存储器,但不可能两边的好处都占着,不可能制造出访问速度又快容量又大的存储器。因此,现代计算机都把存储器分成若干级,称为Memory Hierarchy,按照离CPU由近到远的顺序依次是CPU寄存器、Cache、内存、硬盘,越靠近CPU的存储器容量越小但访问速度越快。
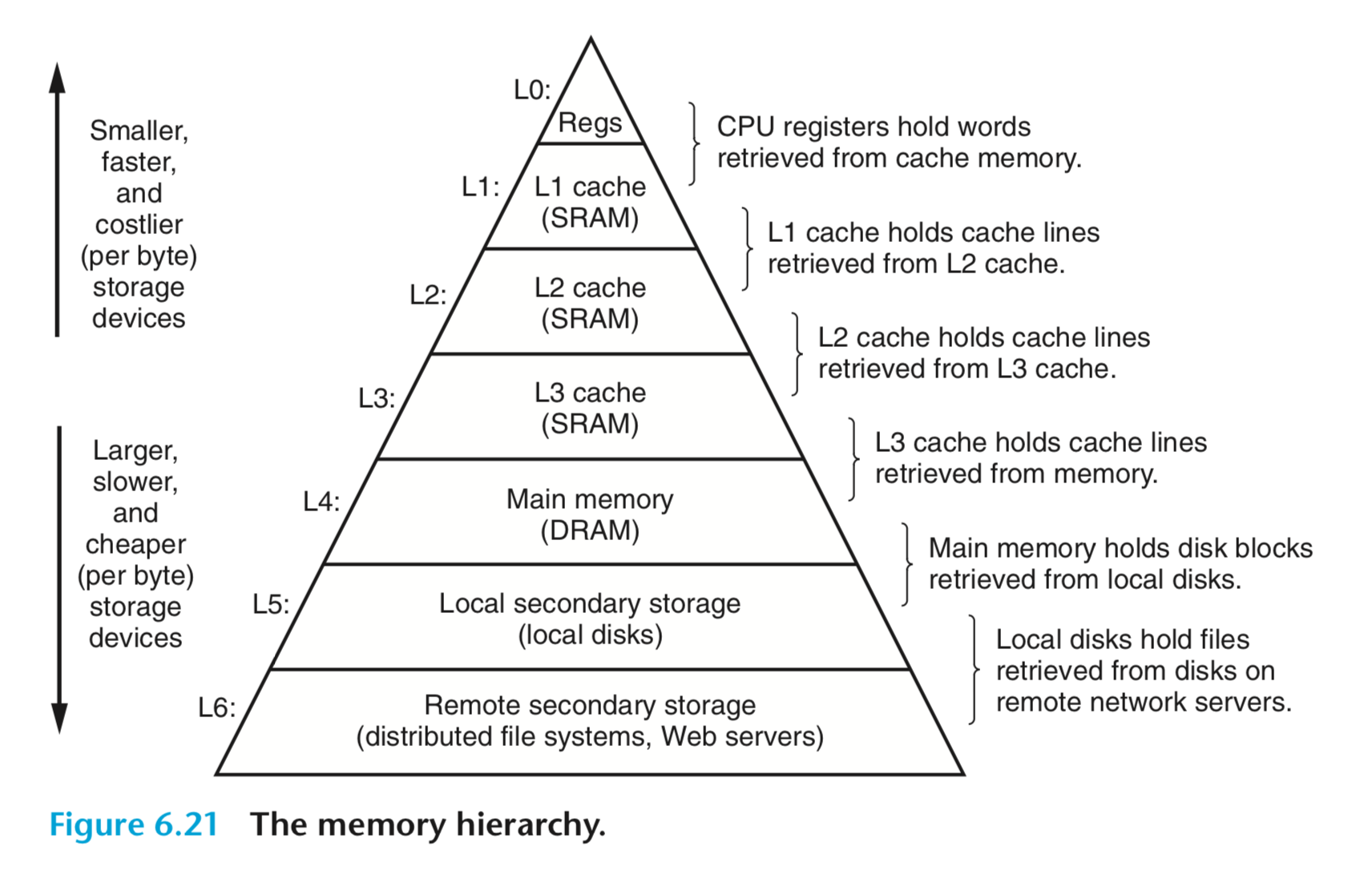
大多数程序的行为都具有局部性(Locality)的特点:它们会花费大量的时间反复执行一小段代码(例如循环),或者反复访问一个很小的地址范围中的数据(例如访问一个数组)。所以预读缓存可以有效的提高程序的运行效率:CPU取一条指令,我把和它相邻的指令也都缓存起来,CPU很可能马上就会取到;CPU访问一个数据,我把和它相邻的数据也都缓存起来,CPU很可能马上就会访问到。
但由于python的数据缺乏局部性的特点,导致于都缓存的失效,以下显示了一个列表内部元素的地址分布情况:
>>> a = [1, 100, 'string', 'zhf']
>>> for element in a:
... print(id(element))
...
4310279600
4310282768
4313350920
4318726608
更加具体的相关内容,可以阅读《深入理解计算机系统》第六章
性能分析工具
cProfile
在进行优化时,我们需要合适的工具来进行性能分析,找到性能的瓶颈,这里推荐使用cProfile模块,官方文档
我们可以在运行python脚本时,使用工具,分析各个调用占用的时间,我们写一个简单的程序:
def fab(num):
if num == 1:
return 1
elif num == 2:
return 1
else:
return fab(num-1) + fab(num-2)
if __name__ == "__main__":
fab(40)
对以上程序进行性能分析:
$ python -m cProfile -s cumulative sample.py
1664082 function calls (4 primitive calls) in 0.370 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.370 0.370 {built-in method builtins.exec}
1 0.000 0.000 0.370 0.370 sample.py:1(<module>)
1664079/1 0.370 0.000 0.370 0.370 sample.py:1(fab)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
- 第一行:1664082个函数调用被监控,其中4个是原生调用(不涉及递归)
- ncalls:函数被调用的次数。如果这一列有两个值,就表示有递归调用,第二个值是原生调用次数,第一个值是总调用次数。
- tottime:函数内部消耗的总时间。(可以帮助优化)
- percall:是tottime除以ncalls,一个函数每次调用平均消耗时间。
- cumtime:之前所有子函数消费时间的累计和。
- filename:lineno(function):被分析函数所在文件名、行号、函数名。
%timeit
在IPython交互界面下,可以使用%timeit查看特定函数调用的时间
In [8]: %timeit b()
774 µs ± 4.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
优化方法
下面从数据结构,算法,程序实现等几个角度总结了常用的性能优化方法,这些方法并不仅限于python
列表
当我们要将一串长度固定的数子放入列表中,有两种方法:
# 方法一
def method1():
a = []
for i in range(100):
a.append(i)
# 方法二
def method2():
a = [0] * 100
for i in range(100):
a[i] = 100
当列表的长度较大时,方法二较方法一有明显的性能优势,原因在于方法一的列表需要不断的动态扩张和重新分配内存空间,关于动态表扩张和收缩的策略,可以看《算法导论》第17章第4节。
以下是cpython 3.6关于list动态分配内存的源代码:
static int
array_resize(arrayobject *self, Py_ssize_t newsize)
{
char *items;
size_t _new_size;
...
_new_size = (newsize >> 4) + (Py_SIZE(self) < 8 ? 3 : 7) + newsize;
items = self->ob_item;
/* XXX The following multiplication and division does not optimize away
like it does for lists since the size is not known at compile time */
if (_new_size <= ((~(size_t)0) / self->ob_descr->itemsize))
PyMem_RESIZE(items, char, (_new_size * self->ob_descr->itemsize));
else
items = NULL;
if (items == NULL) {
PyErr_NoMemory();
return -1;
}
self->ob_item = items;
Py_SIZE(self) = newsize;
self->allocated = _new_size;
return 0;
}
关于这部分的具体解释,可参考博文 动态表扩张和收缩的摊还分析
集合与字典
合适的使用集合与字典能够极大的提升程序的效率和可读性
当需要判断一个元素是否在队列中时,最好用集合,不要用列表
针对列表的in方法,实际是遍历整个列表,复杂度为 $ O(n) $,而对集合与字典本质上是哈希表,对其的in方法复杂度为 $ O(1) $
当需要用if else做大量的分支判断,且分支判断的方法为==时,最好使用字典的方式
"""
原始代码
"""
if not isinstance(func, str):
raise TypeError("Please input a string as cost function name")
if func == "normal_mean":
self.func = normal_mean
elif func == "normal_var":
self.func = normal_val
...
"""
用字典重构
"""
func_dict = {
"normal_mean": normal_mean,
"normal_var": normal_var,
"normal_meanvar": normal_meanvar,
"poisson": poisson,
"exp": exponential
}
if not isinstance(func, str):
raise TypeError("Please input a string as cost function name")
if func in func_dict:
self.func = func_dict[func]
用字典重构后,使代码更加简洁,逻辑清晰且易于维护
尽量避免创建过大的字典
字典的本质是哈希表,关于哈希表的原理,可以阅读《算法导论》第11章。我们知道,哈希表的扩张会消耗大量的时间,而python的dict默认的最小长度是16
每次改变大小时,当哈希表的装载因子大于0.5或小于0.1时,哈希表将重新散列,slot的个数为现有元素的3.3倍,并保证是 $ 2^n $,Python 3.6 源代码如下:
...
#define HASHTABLE_MIN_SIZE 16
#define HASHTABLE_HIGH 0.50
#define HASHTABLE_LOW 0.10
#define HASHTABLE_REHASH_FACTOR 2.0 / (HASHTABLE_LOW + HASHTABLE_HIGH)
...
/* makes sure the real size of the buckets array is a power of 2 */
static size_t
round_size(size_t s)
{
size_t i;
if (s < HASHTABLE_MIN_SIZE)
return HASHTABLE_MIN_SIZE;
i = 1;
while (i < s)
i <<= 1;
return i;
}
...
/* 重新分配哈希表内存空间 */
static void
hashtable_rehash(_Py_hashtable_t *ht)
{
size_t buckets_size, new_size, bucket;
_Py_slist_t *old_buckets = NULL;
size_t old_num_buckets;
new_size = round_size((size_t)(ht->entries * HASHTABLE_REHASH_FACTOR));
...
static int
_Py_hashtable_pop_entry(_Py_hashtable_t *ht, size_t key_size, const void *pkey,
void *data, size_t data_size)
{
...
/* 如果装载因子小于0.1,重新散列 */
if ((float)ht->entries / (float)ht->num_buckets < HASHTABLE_LOW)
hashtable_rehash(ht);
return 1;
}
int
_Py_hashtable_set(_Py_hashtable_t *ht, size_t key_size, const void *pkey,
size_t data_size, const void *data)
{
...
/* 如果装载因子大于0.5,重新散列 */
if ((float)ht->entries / (float)ht->num_buckets > HASHTABLE_HIGH)
hashtable_rehash(ht);
return 0;
}
尾递归
当我们调用一个函数时,cpu会在内存空间上开辟一个对应的函数栈帧,栈帧中保存函数的局部变量、框架等,当函数调用结束返回结果后,栈帧会被释放。我们写一个简单的C语言程序:
int bar(int c, int d)
{
int e = c + d;
return e;
}
int foo(int a, int b)
{
return bar(a, b);
}
int main(void)
{
foo(2, 3);
return 0;
}
对上述代码进行编译,并反汇编,得到汇编代码,查看相关内容:
08048394 <bar>:
int bar(int c, int d)
{
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
int e = c + d;
804839a: 8b 55 0c mov 0xc(%ebp),%edx
804839d: 8b 45 08 mov 0x8(%ebp),%eax
80483a0: 01 d0 add %edx,%eax
80483a2: 89 45 fc mov %eax,-0x4(%ebp)
return e;
80483a5: 8b 45 fc mov -0x4(%ebp),%eax
}
80483a8: c9 leave
80483a9: c3 ret # 退出栈帧
080483aa <foo>:
int foo(int a, int b)
{
80483aa: 55 push %ebp
80483ab: 89 e5 mov %esp,%ebp
80483ad: 83 ec 08 sub $0x8,%esp
return bar(a, b);
80483b0: 8b 45 0c mov 0xc(%ebp),%eax
80483b3: 89 44 24 04 mov %eax,0x4(%esp)
80483b7: 8b 45 08 mov 0x8(%ebp),%eax
80483ba: 89 04 24 mov %eax,(%esp)
80483bd: e8 d2 ff ff ff call 8048394 <bar> # 进入函数bar的栈帧
}
80483c2: c9 leave
80483c3: c3 ret # 退出栈帧
函数调用的顺序如下:
- 调用
foo,分配对应函数栈 - 运行到
80483bd,调用函数bar,分配对应函数栈 - 运行到
80483a9,退出bar()的函数栈帧 - 运行到
80483c3,退出foo()的函数栈帧
当调用递归函数时,每次重复调用函数都会新开一个函数栈,导致内存大量被占用,如果对代码进行尾递归的优化,能够提高内存空间的使用效率,代码如下:
"""
原始代码
"""
def recsum(x):
if x == 1:
return x
else:
return x + recsum(x - 1)
"""
尾递归优化后代码
"""
def tailrecsum(x, running_total=0):
if x == 0:
return running_total
else:
return tailrecsum(x - 1, running_total + x)
尾递归的具体内容可参考文章 尾调用优化
算法复杂度优化
分析算法的总体复杂度,找到更优秀的算法实现。
"""
未修改前的代码
"""
def merge(L,k):
n = len(L)
dataMergeList = []
for i in range(n-1):
for j in range(i+1,n):
L1 = list(L[i])[:k]
L2 = list(L[j])[:k]
L1.sort()
L2.sort()
if L1 == L2:
dataMergeList.append(L[i] | L[j])
return dataMergeList
"""
修改后
"""
def merge(L,k):
n = len(L)
newlst = [None] * n
for i, lst in enumerate(L):
newlst[i] = sorted(list(lst)[:k])
dataMergeList = []
for i in range(n-1):
for j in range(i+1,n):
L1 = newlist[i]
L2 = newlist[j]
if L1 == L2:
dataMergeList.append(L[i] | L[j])
return dataMergeList
优化前代码的时间复杂度为 $O(n^2k\log k) $, 优化后代码时间复杂度为 $O(max(n ^ 2, n k \log k) )$,代码在实际的运行中获得数倍的性能提升。
数学优化
采用数学方法,优化复杂的计算过程,是提成程序效率的最好办法,但应用场景较少。一个例子就是通过数学方法优化斐波那契数列的计算:
预计算
当程序中存在大量重复的计算时,我们可以把这些计算的结果预先算法,存储在列表中。当需要时直接进入列表查询结果,用寻址代替浮点数的计算。
例子
将RGB颜色转化为灰值的计算:
$$ Gray = 0.299R + 0.587G + 0.114B $$
由于R,G,B均为 0~255的整型变量,因此可以预先计算好所有结果,并将其存放到一个大的数组中。由于我们需要对每个像素点的数值进行变换,预计算可以极大的优化整体性能。
使用c语言
使用c语言编写的依赖包
python数值计算中有大量的依赖包是使用c语言编写的,使用这些依赖包能够极大的提高运行效率,主要原因如下:
- c语言的内存分配紧凑,能够很好的利用L1/L2缓存的预读取加速
- Python解释器翻译的c语言很冗长,运行效率低下
用cpython编写程序
使用cpython在python程序内编写,可以明显提高运行效率。
将c程序封装python接口
python提供了丰富的C API,我们可以直接根据这些接口,封装c语言,然后用类似依赖包的方式直接调用c程